library(class)
library(psych)
fdata<-read.table("football_data.txt", header = T)
head(fdata)
## group WDIM CIRCUM FBEYE EYEHD EARHD JAW
## 1 1 13.5 57.15 19.5 12.5 14.0 11
## 2 1 15.5 58.42 21.0 12.0 16.0 12
## 3 1 14.5 55.88 19.0 10.0 13.0 12
## 4 1 15.5 58.42 20.0 13.5 15.0 12
## 5 1 14.5 58.42 20.0 13.0 15.5 12
## 6 1 14.0 60.96 21.0 12.0 14.0 13
#labels: 1: high school football players,
# 2: college football players,
# 3: non-football players in college
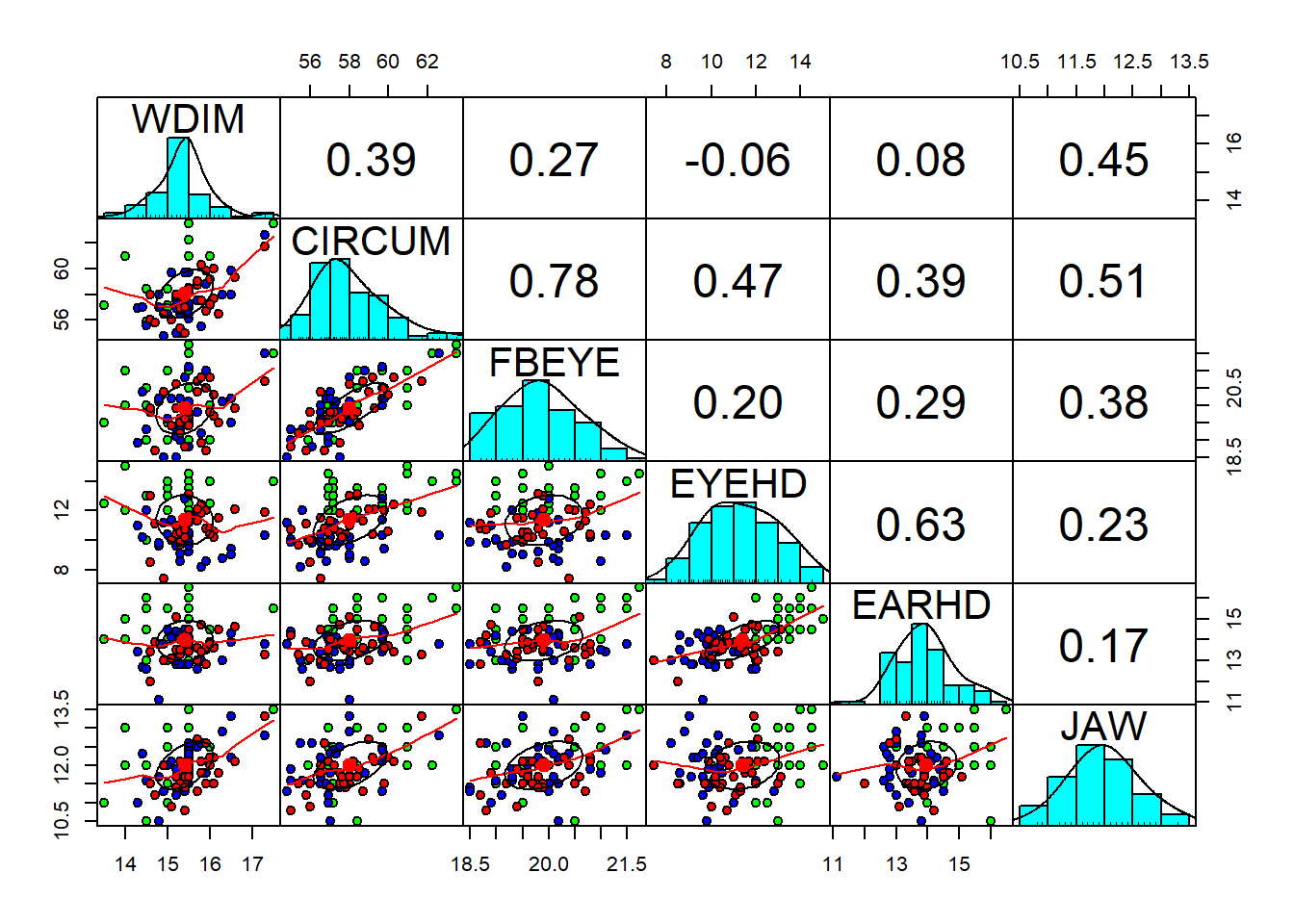
cor(fdata)
## group WDIM CIRCUM FBEYE EYEHD EARHD
## group 1.0000000 0.23434774 -0.2548989 -0.1645302 -0.52275886 -0.44475644
## WDIM 0.2343477 1.00000000 0.3865501 0.2708419 -0.06085635 0.07884543
## CIRCUM -0.2548989 0.38655006 1.0000000 0.7789327 0.46982158 0.39087246
## FBEYE -0.1645302 0.27084189 0.7789327 1.0000000 0.20036649 0.28708706
## EYEHD -0.5227589 -0.06085635 0.4698216 0.2003665 1.00000000 0.63038948
## EARHD -0.4447564 0.07884543 0.3908725 0.2870871 0.63038948 1.00000000
## JAW -0.2988388 0.45450662 0.5056499 0.3842090 0.23240843 0.17332363
## JAW
## group -0.2988388
## WDIM 0.4545066
## CIRCUM 0.5056499
## FBEYE 0.3842090
## EYEHD 0.2324084
## EARHD 0.1733236
## JAW 1.0000000
pairs.panels(fdata[2:7],
gap=0,
bg=c("green", "blue", "red")[fdata$group],
pch=21)
#Partition for training and test data
set.seed(100)
ind <- sample(2, nrow(fdata),replace=T, prob = c(0.7,0.3))
train <- fdata[ind==1,]
test <- fdata[ind==2,]
train.group <- train$group
# Model Fit
knn.pred =knn(train,test, train$group, k=4)
knn.pred
## [1] 1 1 1 1 1 1 1 3 3 3 2 2 3 2 2 2 2 3 3 3 3 3 3 2 3
## Levels: 1 2 3
#Accuracy Probability
#Accuracy on test data
mean(knn.pred == test$group)
## [1] 0.76
#Confusion Matrix for Test Data
table(knn.pred,test$group)
##
## knn.pred 1 2 3
## 1 7 0 0
## 2 0 5 2
## 3 0 4 7
#Analysis for misclassiffed data
length(test$group)
## [1] 25
test$group
## [1] 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3
wp <- which(knn.pred != test$group)
wp
## [1] 8 9 10 13 17 24
test[wp,]
## group WDIM CIRCUM FBEYE EYEHD EARHD JAW
## 32 2 15.4 59.7 20.0 12.8 14.5 11.3
## 34 2 14.3 56.9 18.9 11.0 13.4 11.0
## 36 2 15.2 57.5 18.5 9.9 12.8 11.4
## 43 2 15.7 57.5 19.8 11.8 12.6 12.5
## 63 3 15.3 55.4 19.2 9.7 13.3 11.5
## 87 3 15.4 55.0 18.8 10.7 14.2 10.8